Voz
La voz es la entrada principal de dIKta.me. Pulsa un atajo, habla y la app captura tu audio, lo transcribe con un motor de Reconocimiento de Voz (STT) y (opcionalmente) lo procesa con un modelo de IA antes de enviar el resultado a donde te sea útil.
La voz se combina con casi cualquier salida. La misma frase hablada puede convertirse en texto dictado, una reescritura refinada, una respuesta a una pregunta, una traducción, una nota guardada o una nota de voz añadida a una imagen — según el atajo que pulses.
Cómo capturar voz
Cada acción por voz usa un atajo global que puedes pulsar desde cualquier aplicación, en cualquier momento. Tu cursor permanece donde está; la app trabaja en segundo plano.
| Atajo | Acción | Página de salida |
|---|---|---|
Ctrl+Alt+D | Dictar — voz → texto formateado en el cursor | Dictar |
Ctrl+Alt+A | Preguntar — pregunta hablada → respuesta de IA en notificación | Preguntar |
Ctrl+Alt+T | Traducir — voz en un idioma → texto en otro | Traducir |
Ctrl+Alt+N | Nota — voz → línea añadida a tu archivo de notas | Nota |
Ctrl+Alt+Q | Chat Rápido — turno de voz en una conversación en curso | Chat Rápido |
Todos los atajos son reasignables en Configuración → Atajos de Teclado.
El Panel de Control durante la entrada de voz
Cuando activas una acción de voz, el Panel de Control flotante se actualiza en tiempo real:
Ver todos los estados del Panel de Control
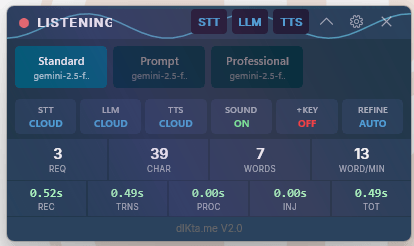
- Listo — inactivo, esperando un atajo
- Escuchando — grabando audio ahora mismo
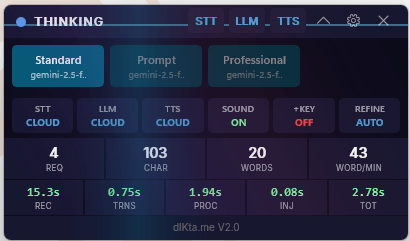
- Pensando — transcripción y procesamiento de IA en curso
- Colapsado / Rodillo de Inactividad — tras un periodo de inactividad la barra se encoge y cicla entre estado, logo + reloj y clima

Streaming vs. por lotes
Por defecto, la voz funciona en modo por lotes: dIKta.me graba hasta que paras y luego envía el clip completo al proveedor STT. Esto es lo que habilita el post-procesamiento con LLM (Refinar, Preguntar, Traducir).
El modo streaming (solo Deepgram) envía audio en tiempo real e inyecta palabras mientras hablas. Es más rápido, pero omite el formateo del LLM — lo que dices es lo que aparece. Activa streaming en Configuración → Motor IA → Reconocimiento de Voz.
Voz local vs. nube
La entrada de voz funciona totalmente sin conexión si eliges proveedores locales:
- STT en la nube — Deepgram (créditos de wallet o BYOK)
- STT local — Whisper ejecutándose en tu equipo (ningún dato sale de tu máquina)
Alterna entre ellos por preset de dictado en Configuración → Presets de Dictado, o globalmente en Configuración → Motor IA.