Pantalla
Tu pantalla es una entrada. Pulsa el atajo de Visión, atenúa la pantalla, arrastra una región (o captura una ventana o monitor completo), y la imagen se convierte en materia prima para una IA que puede describirla, extraer su texto, analizar su estructura o añadirla a una nota.
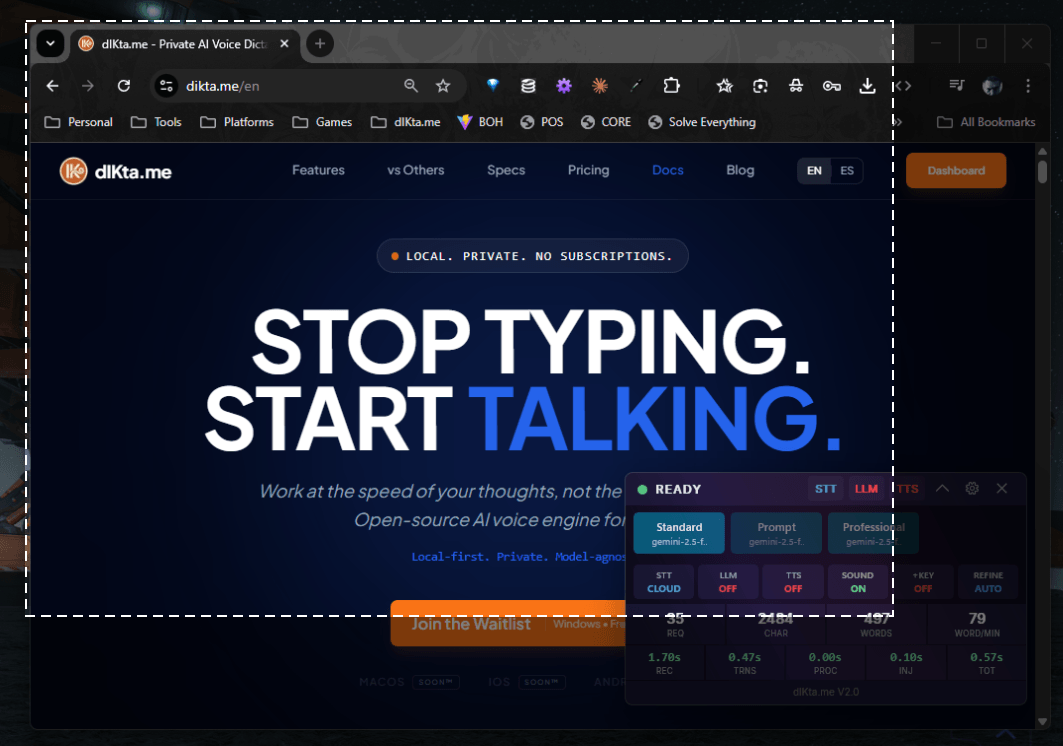
La visión se combina naturalmente con la voz. Tras capturar, puedes grabar una pregunta hablada (*"¿Qué significa este error?"*, *"Resume los datos de esta tabla"*) antes de que la IA procese la imagen.
Cómo capturar la pantalla
Pulsa el atajo de Visión desde cualquier app:
Ctrl+Alt+S (por defecto, reasignable en Configuración → Atajos)
La pantalla se atenúa y aparece un overlay de recorte transparente con una barra de ayuda:

| Gesto | Qué captura |
|---|---|
| Clic en una ventana | Esa ventana específica de la aplicación |
| Clic y arrastrar | Una región rectangular personalizada |
| Shift + arrastrar | Una forma libre |
Pulsar F | El monitor activo completo |
Pulsar A | Todos los monitores como una imagen ancha |
Pulsar Esc | Cancela y vuelve a tu trabajo |
Tras la selección el overlay se cierra y se abre el Panel de Acciones de Visión.
El Panel de Acciones de Visión
El panel de acciones te permite (opcionalmente) escribir o grabar una pregunta, y luego elegir qué debe hacer la IA con la captura:

Selectores de fuente y modo de captura


Salidas que consumen la pantalla
| Acción | Qué hace | Destino |
|---|---|---|
| OCR | Extrae cada carácter de la captura | Portapapeles / cursor |
| Describir (Clip / Chat) | La IA describe lo que ve en lenguaje natural | Notificación / Chat Rápido |
| Guardar | Escribe la captura en disco | Carpeta de guardado configurada |
| Nota | Añade la imagen + tu descripción hablada a tu archivo de notas | Nota |
| Chat | Adjunta la imagen a una conversación de Chat Rápido | Chat Rápido |
Selector de color y captura de video
La familia del atajo de Visión también incluye dos herramientas especializadas:
- Selector de Color — un cursor con magnificador de píxeles que muestrea colores de tu pantalla, con una bandeja de muestras y atajos de teclado.
- Barra de Grabación de Video — una pequeña barra/temporizador flotante para capturar grabaciones cortas de pantalla.

Selector de color en detalle
Los tooltips del magnificador de un solo píxel muestran los valores hex y RGB en vivo según mueves el cursor:
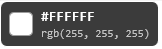
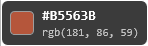
Las muestras se acumulan al hacer clic:

Visión local vs. nube
La visión se ejecuta sobre un modelo de IA multimodal:
- Nube — Gemini Flash (wallet o BYOK), OpenAI GPT-4o con BYOK
- Local — Ollama con
minicpm-vomoondream(OCR soportado completo solo enminicpm-v)
Configura en Configuración → Motor IA → Visión.
Los modelos de Visión locales son más pequeños y cuantizados — la precisión del OCR y el análisis de contexto largo son notablemente más fuertes en la ruta de nube.