Ajustes del Motor de IA (AI Engine)
La pestaña Motor de IA (AI Engine) es el cerebro de tu experiencia con dIKta.me. Controla qué motores de Reconocimiento de Voz (STT), Modelo de Lenguaje (LLM) y Texto a Voz (TTS) manejan cada pipeline. La pestaña tiene un diseño maestro-detalle — elige una categoría a la izquierda, configúrala a la derecha.
**Nube vs. Local**: puedes cambiar el entorno activo directamente desde el overlay del Panel de Control sin abrir ajustes. Cada sub-sección de abajo tiene configuraciones independientes de Nube y Local para que puedas mezclar — por ejemplo, STT en nube + LLM local.
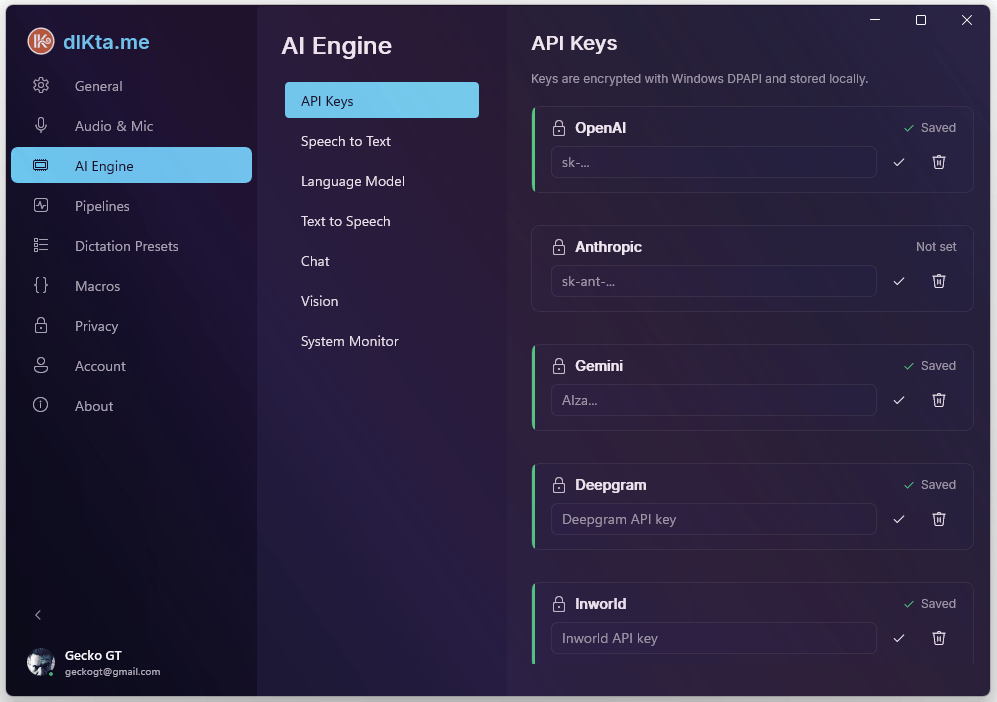
Claves API
La sección Claves API es una bóveda cifrada única para cada proveedor en la nube. Las claves se guardan con Windows DPAPI al grabar, así que quedan atadas a tu cuenta de usuario y a tu máquina. Úsala cuando vayas por la ruta BYOK (trae tu propia clave) y quieras que Gemini, Anthropic, OpenAI, Deepgram, Inworld o OpenRouter respondan directamente en lugar de pasar por el wallet.
Captura: Bóveda de Claves API
Reconocimiento de Voz (STT)
Esta sección elige qué motor convierte tu voz en texto. Cada ruta — Nube y Local — tiene su propia selección, así que cambiar de entorno es un solo toggle.
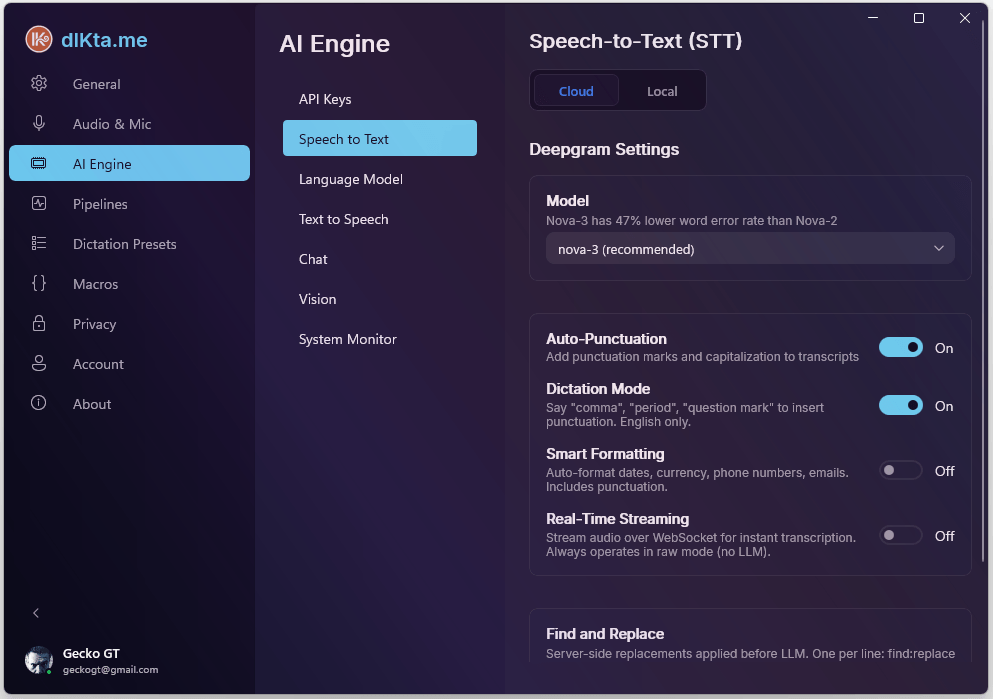
STT en la Nube
Deepgram es el proveedor principal de STT en la nube. Soporta tanto batch (enviar el clip completo) como streaming (enviar chunks por WebSocket mientras hablas). El streaming es lo que hace que el dictado se sienta instantáneo, pero omite el formateo por LLM por diseño — las palabras transmitidas se inyectan sin procesar.
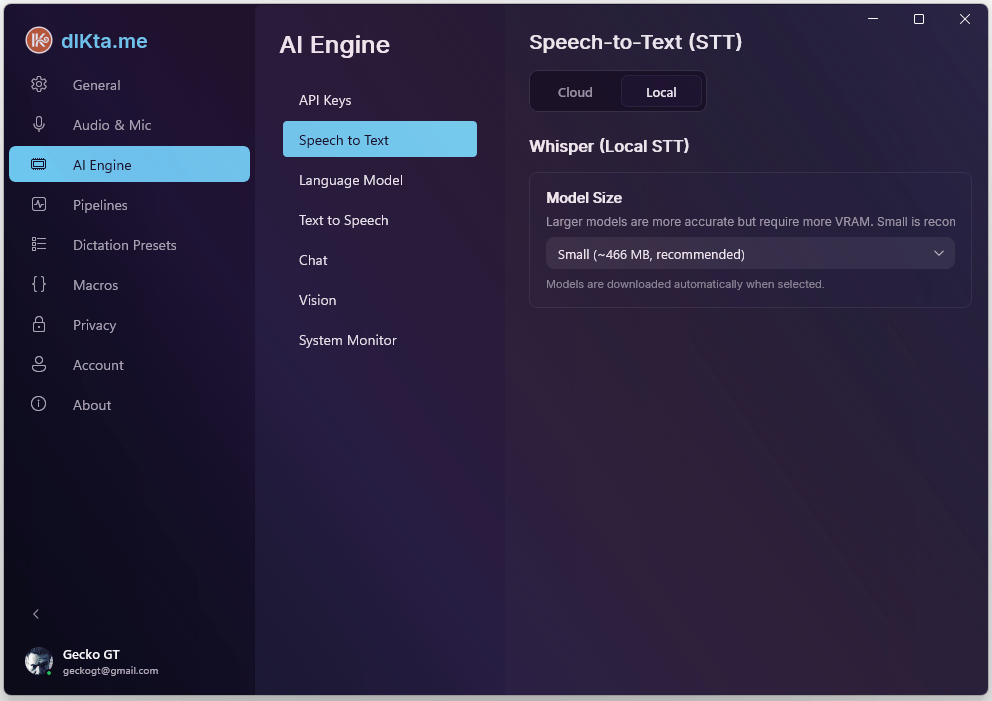
STT Local
Whisper corre enteramente en tu equipo. La primera vez que eliges un tamaño de modelo, dIKta.me descarga el archivo ONNX correspondiente; después de eso no hay tráfico de red en absoluto. Modelos más grandes son más precisos pero requieren más VRAM — el selector recomienda Small (~466 MB) como balance por defecto.
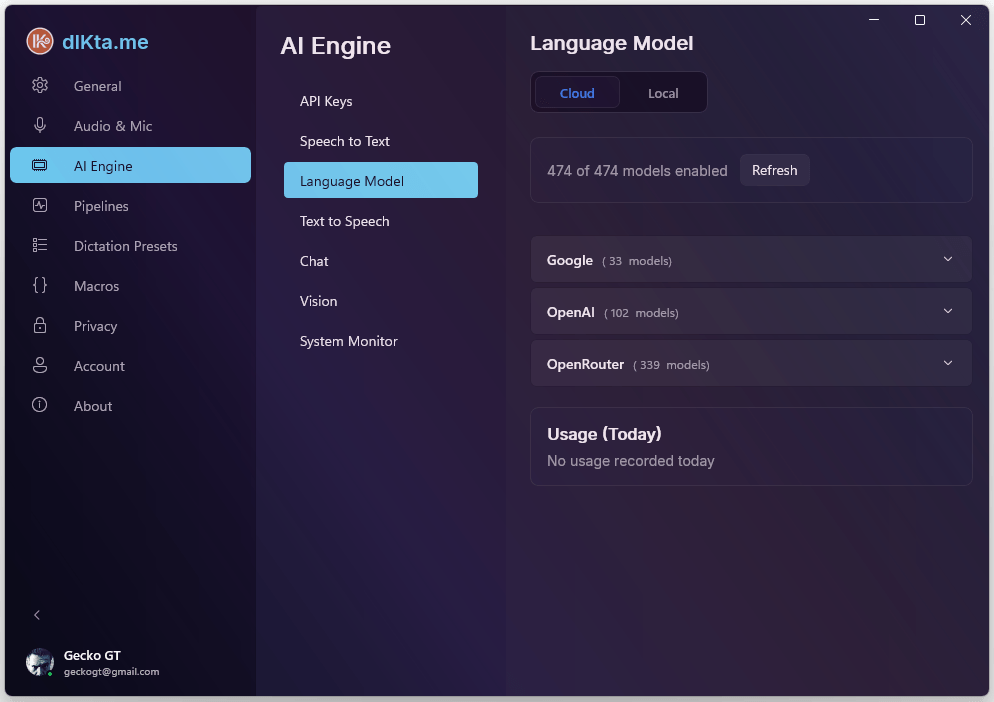
Modelo de Lenguaje (LLM)
Esta sección controla el modelo que limpia, formatea, reescribe, responde y traduce tu texto. Es el paso que convierte "transcripción en bruto" en "escritura terminada".
LLM en la Nube
Elige un proveedor (Gemini / Anthropic / OpenAI / OpenRouter / Requesty) y un modelo dentro de él. Gemini 2.5 Flash es el predeterminado para usuarios Wallet por su relación velocidad-por-crédito. Con BYOK puedes elegir cualquier modelo que el proveedor exponga.
LLM Local (Ollama)
Ollama es el motor LLM local. dIKta.me habla con Ollama en http://localhost:11434 por defecto; si ejecutas Ollama en otra máquina de tu LAN, apunta el Host URL a esa IP. Pulsa Test Connection para verificar.
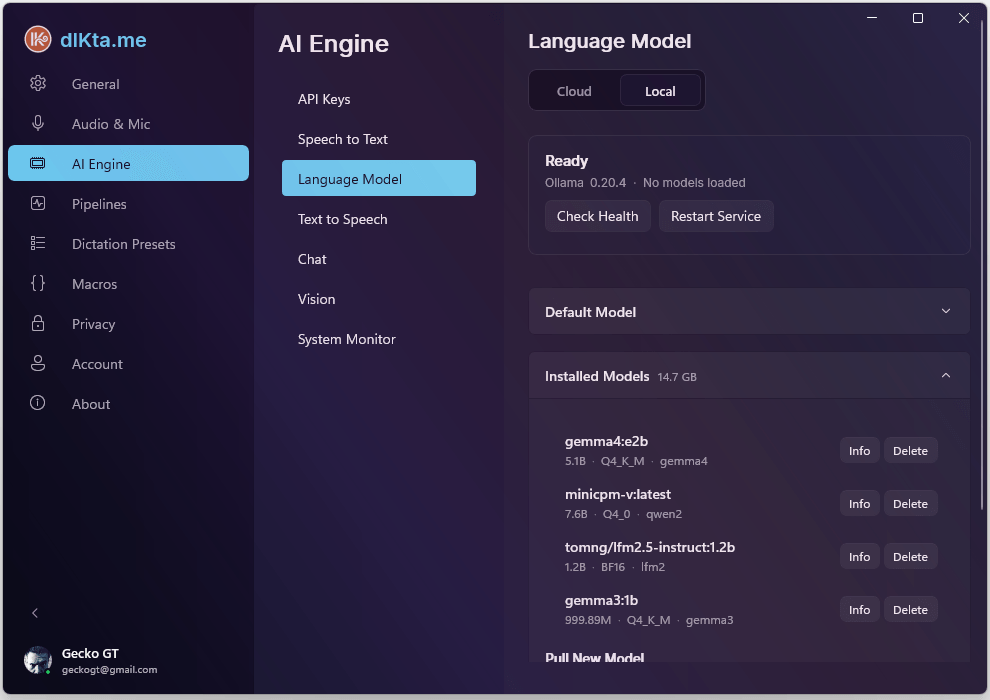
La Biblioteca de Modelos te permite buscar e instalar cualquier modelo compatible con Ollama (Gemma, Llama, Mistral, Phi, Qwen, etc.) sin abrir nunca un terminal. El panel Avanzado expone la ventana de contexto (num_ctx) y un toggle de auto-warmup que mantiene tu modelo por defecto calentito en memoria para una primera latencia de dictado más rápida.
Captura: Biblioteca de Modelos + panel Avanzado de Ollama
Los modelos instalados de Ollama aparecen en todos los selectores de LLM Local — Presets de Dictado, Pipelines de Utilidad y Chat — todos extraen de la misma lista. Si borras un modelo aquí desaparece de esos selectores al instante.
Texto a Voz (TTS)
TTS es un canal de salida opcional. Cuando se activa, dIKta.me puede leer respuestas de Ask en voz alta, vocalizar respuestas de Chat Rápido, pronunciar resultados de Traducir o leer cualquier texto resaltado bajo demanda (Ctrl+Alt+F). Nunca retrasa la inyección de texto — el audio se reproduce en paralelo.
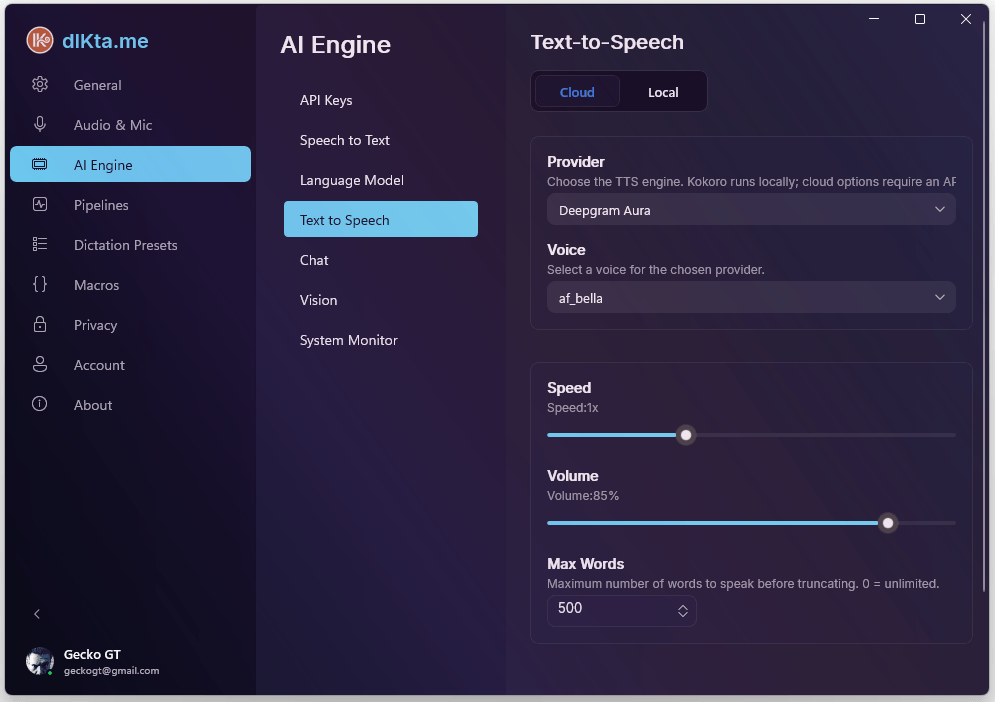
TTS en la Nube
Se soportan cuatro proveedores en la nube. La mayoría elige el que coincida con una clave que ya tenga:
- Deepgram Aura-2 — reutiliza tu clave STT de Deepgram.
- Gemini TTS — reutiliza tu clave LLM de Gemini. Voces ultra realistas.
- OpenAI TTS — reutiliza tu clave de OpenAI.
- Inworld TTS-1.5 — calidad premium, baja latencia; necesita su propia clave.
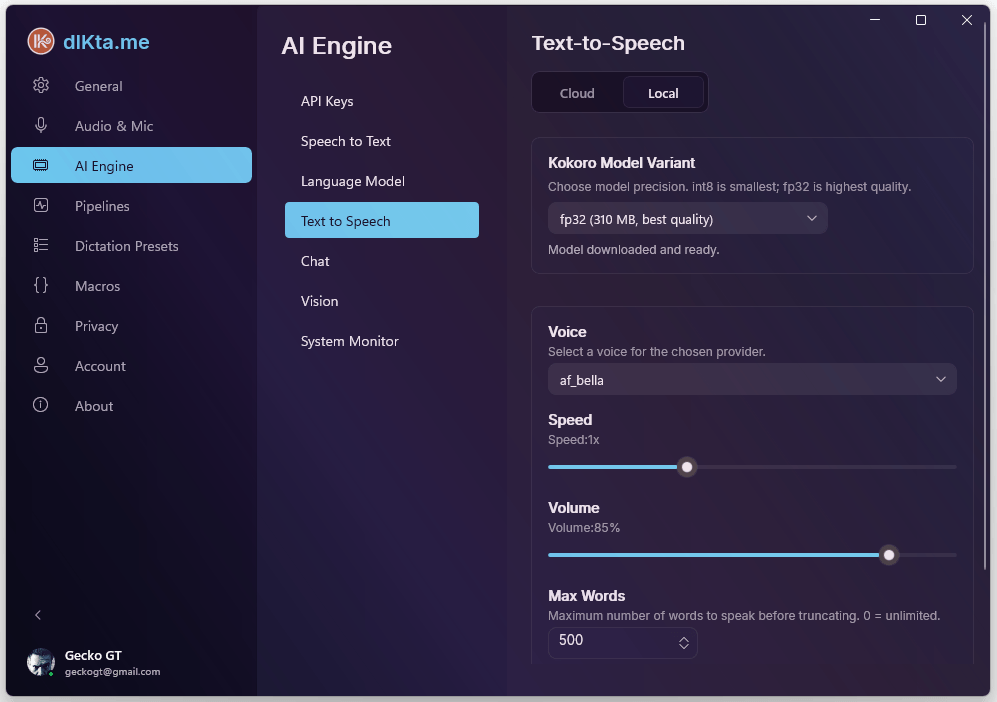
TTS Local (Kokoro)
Kokoro es un sintetizador de voz basado en ONNX que corre en tu CPU. El modelo pesa ~88 MB y se descarga en el primer uso; después no requiere red. La calidad de voz es sorprendentemente buena para el tamaño.
TTS está **desactivado por defecto**. Actívalo solo si quieres salida hablada — activarlo nunca fuerza audio; cada función (Ask, Chat, Translate, Leer Selección, Notificaciones) tiene su propio toggle bajo **Pipelines → Hablar (TTS)**.
Chat
Controla el modelo subyacente del overlay de Chat Rápido y los valores por defecto del prompt del sistema. El modelo aquí se usa en cada conversación de Chat Rápido a menos que lo sobreescribas por sesión.
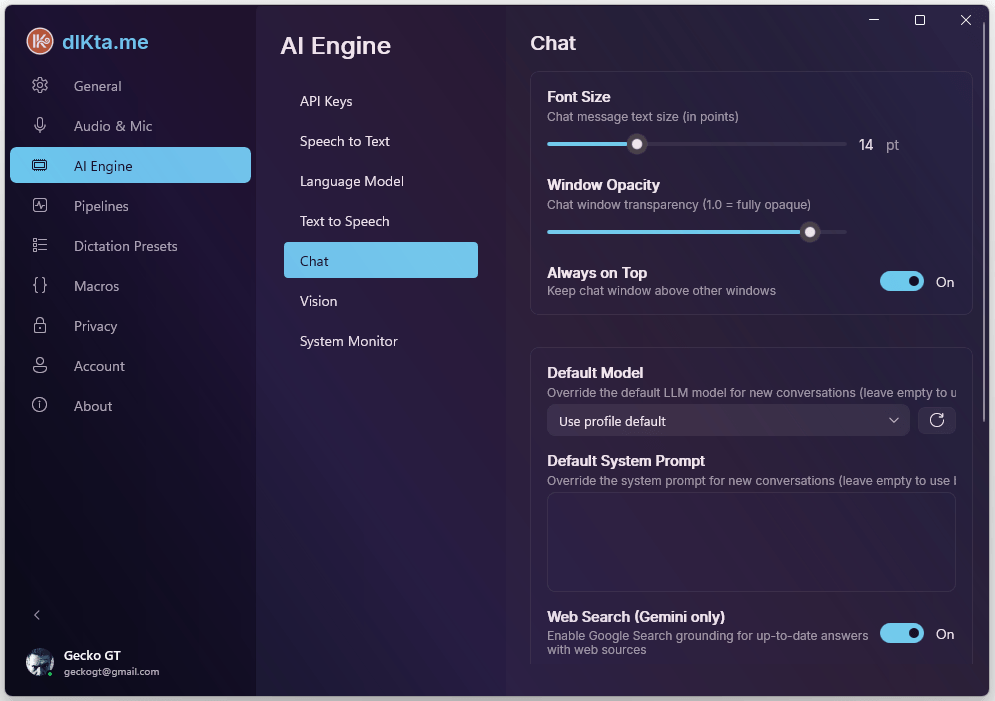
La vista de detalle de modelo muestra cada opción que el proveedor seleccionado expone (ej., Gemini Pro Latest vs. Flash Latest), más límites por conversación de tokens e historial.
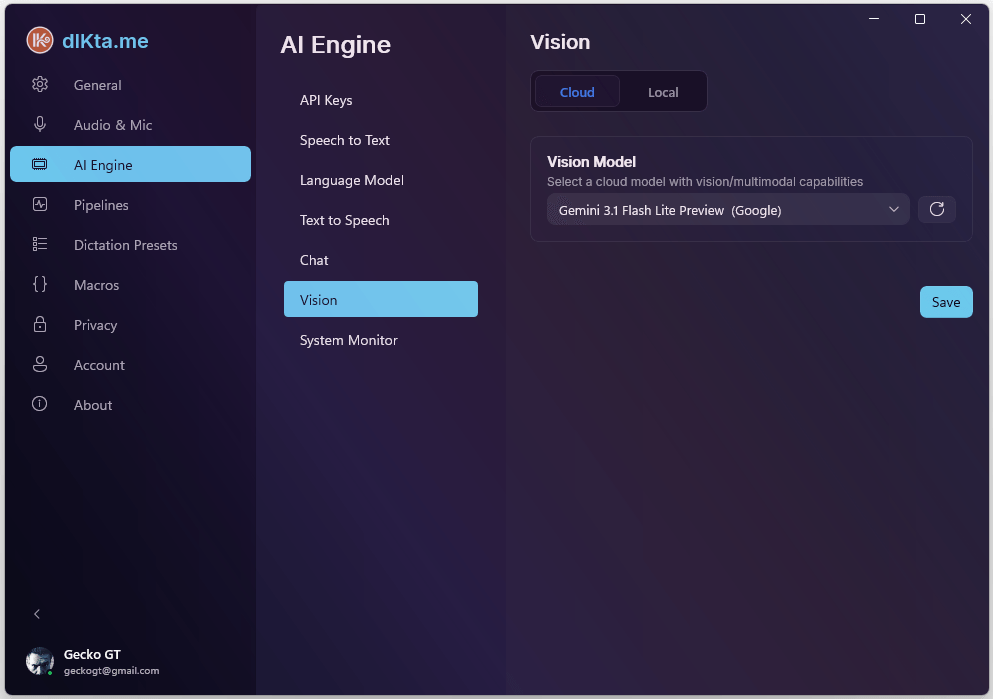
Visión
Visión tiene su propia selección de modelo porque los modelos multimodales no están disponibles universalmente entre proveedores. La ruta Nube dirige a Gemini Flash u OpenAI GPT-4o; la ruta Local dirige a un modelo de visión de Ollama como minicpm-v o moondream.
Visión en la Nube
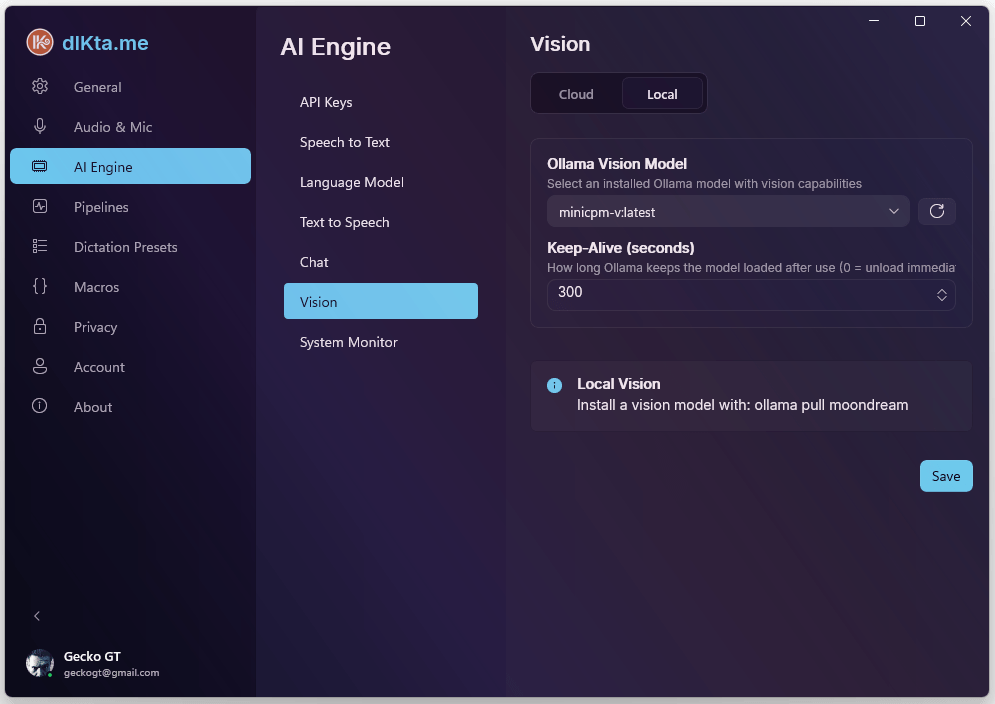
Visión Local
minicpm-v soporta OCR, descripción y Q&A. moondream es más ligero pero con OCR limitado — úsalo solo para descripciones rápidas.
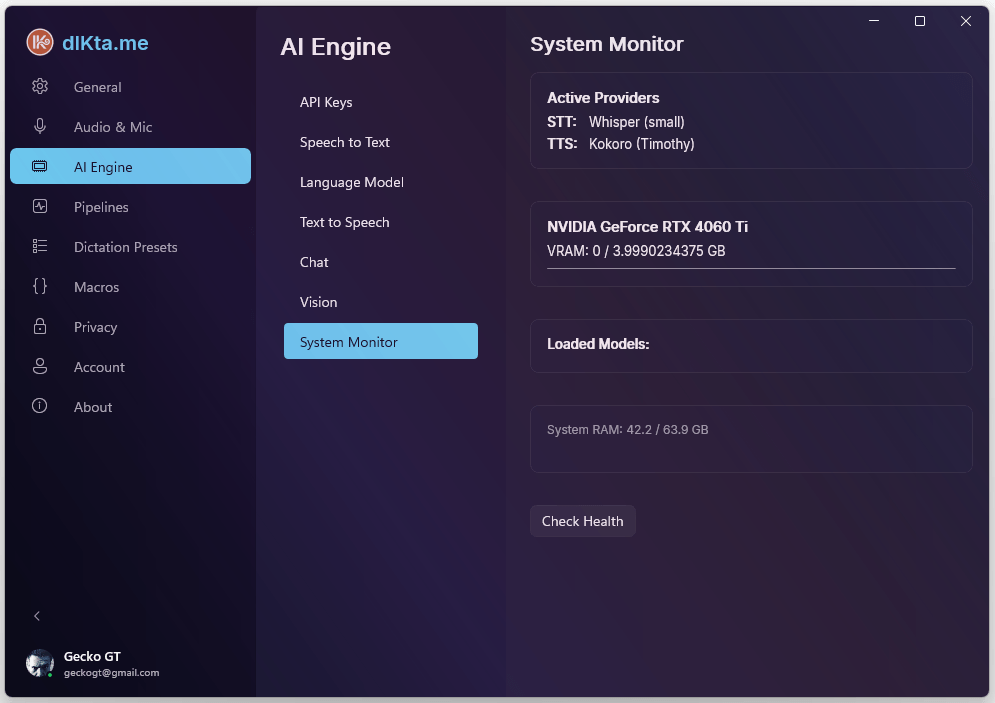
Monitor del Sistema
La última sub-pestaña es una lectura en vivo: salud del daemon de Ollama, estado actual de la GPU, uso de VRAM, tamaño de la caché de modelos y un botón de warmup. Es útil cuando estás diagnosticando latencia de modo local o decidiendo si tienes margen para correr un modelo más grande.
Relacionado
- Presets de Dictado — sobreescrituras de modelo por preset que extraen de la misma lista de proveedores
- Pipelines — sobreescrituras de modelo por pipeline (Ask / Refine / Translate / Note / Vision / Speak)